A guide to understanding commonly used LLM Agent architectures and their distinct advantages and disadvantages: Multi‑Agents, Plan-and-Execute, ReWOO, Tree-of-Thoughts, and ReAct

Building an AI agent to tackle complex tasks requires more than just prompting a single large language model (LLM) for an answer. Recent research and frameworks (like LangChain’s LangGraph) have introduced various architectures to extend an LLM’s capabilities. These architectures help break down problems, integrate external knowledge, and coordinate reasoning steps. In this post, we’ll explore several prominent agent patterns, ReAct (Reason + Act), Multi-Agent systems, Plan-and-Execute, ReWOO (Reasoning Without Observation) and Tree-of-Thoughts and discuss when to use each approach.
Imagine you’re building an AI assistant to answer a complex research question: “Who won the 2024 Australian Open, and what is their hometown? Also, did that person collaborate with any researchers from University X?”). Answering this involves multiple steps: finding the tennis winner, finding their hometown, then checking for academic collaborations – a mix of factual lookup and multi-step reasoning. Let’s see how each architecture could approach such a task, and what unique strengths they bring.
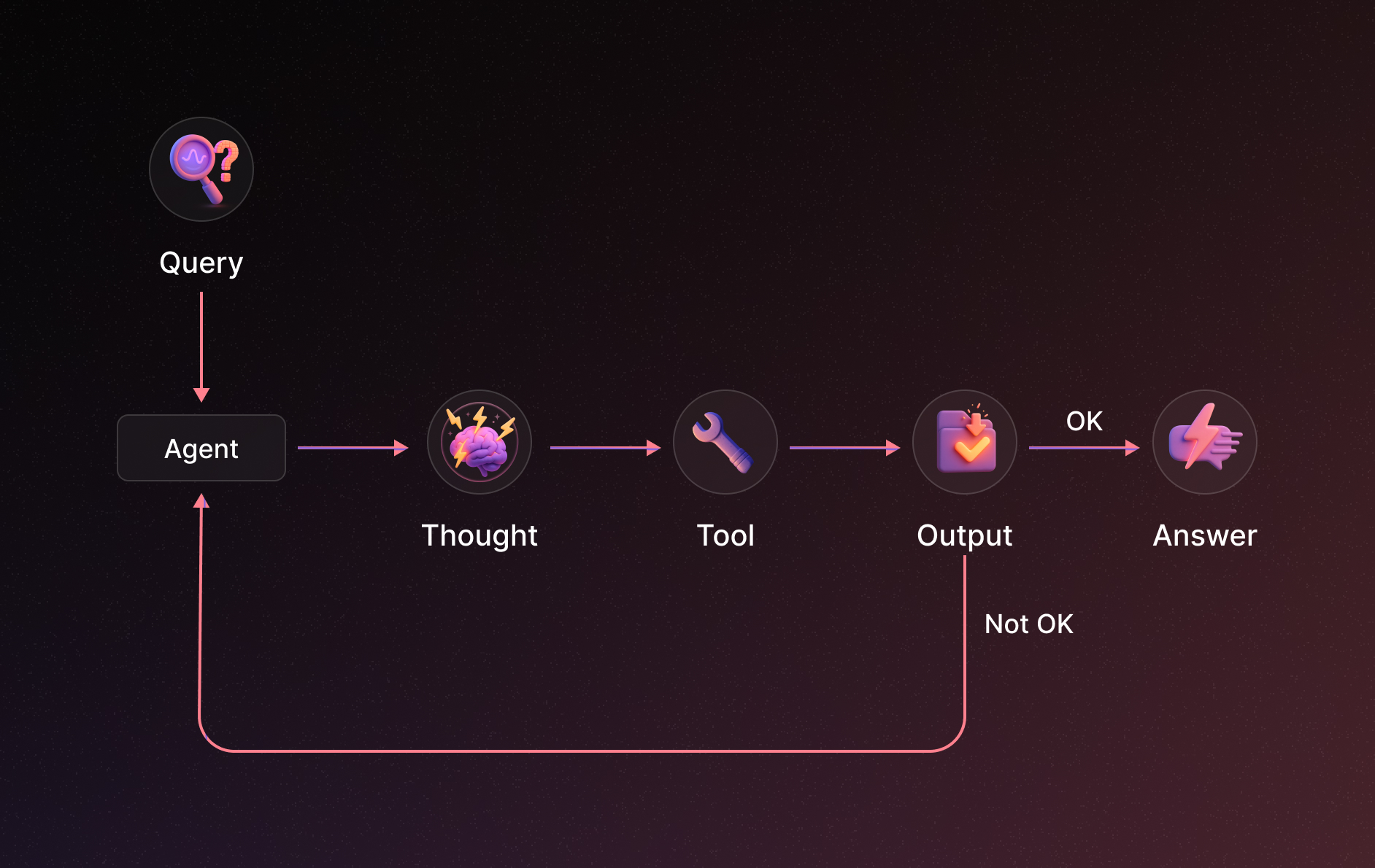
ReAct is one of the earliest and most influential agent patterns for LLMs. ReAct stands for “Reasoning and Acting” and it marries the idea of chain-of-thought reasoning with tool use. A ReAct agent operates in a loop that goes: Thought → Action → Observation, and then repeats this cycle until the task is complete. In simpler terms, the agent thinks out loud, decides on an action (like calling a tool or giving a final answer), observes the result of that action, and then uses that new information to inform the next thought.
To illustrate, let’s apply ReAct to our example question (winner and hometown and collaboration):
This sequence shows how ReAct allows the agent to adapt at each step based on observations. If the first search had already included hometown info, the agent might have skipped a step. If the collaboration search turned up something unexpected (say he did participate in an event at University X), the agent would incorporate that into the answer. This dynamic looping is what gives ReAct its robustness: it closely mimics how a human problem-solver alternates between thinking and doing, adjusting plans on the fly.
Key characteristics of ReAct:
When to use ReAct:
This pattern is a great default for many scenarios where an LLM needs to use tools or perform multi-step reasoning but you don’t have a very long or well-defined plan from the outset. It’s particularly useful if each next step depends heavily on what you find in the previous step. If the task has a solution a few steps away and you won’t need an elaborate plan or parallel steps, ReAct provides a simple and effective control flow.
Most frameworks (LangChain, LangGraph, etc.) support ReAct-style agents readily, and it’s often the starting point for tool-using agent development. In LangGraph’s context, for example, create_react_agent is a utility that sets up an agent with given tools and the ReAct prompt structure. Under the hood, the agent will loop through Thought/Action/Observation until it emits a final answer. This design pattern has influenced many derivatives and enhancements (like ReWOO, Reflexion, etc.), but it remains a foundational technique for “interactive” LLM agents.
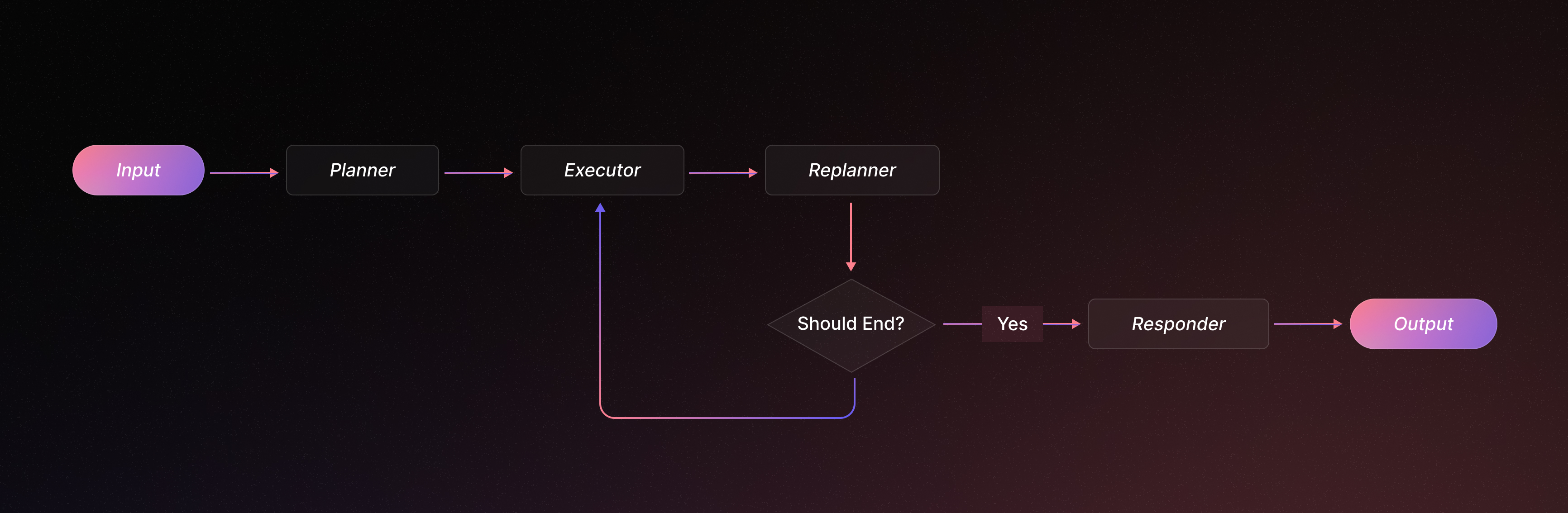
If a task is complex and requires long-term planning, a single LLM agent might struggle to keep the goal in sight by reasoning one step at a time. Plan-and-Execute architectures address this by explicitly planning out a multi-step solution first, then executing each step sequentially. This paradigm is inspired by the “Plan-and-Solve” approach in recent research. It usually involves two phases:
Advantages: A plan-and-execute agent has two big strengths: (1) it enforces explicit long-term planning (which even advanced LLMs can struggle with if left to improvise step-by-step), and (2) it lets you use different models for different stages. For instance, you could use a powerful (but slower) LLM to devise the plan, and a smaller (cheaper) model to carry out each execution step. This way, the heavy lifting of strategy is done by the best reasoning model, but repetitive sub-tasks can be handled more efficiently.
Compared to a ReAct agent that “thinks” one step, acts, then re-thinks in a loop, plan-and-execute commits to a full strategy up front. This can make it more efficient in terms of API calls – the agent doesn’t have to repeat the entire conversation history to the LLM at every single step, since the plan is decided in one go. However, the trade-off is that if the initial plan is flawed or the task environment changes, the agent must detect that and replan. Plan-and-execute works best for tasks where a reasonable plan can be formulated initially and the problem is complex enough to warrant that planning (e.g. coding a multi-module program, performing a research project, or our multi-part question). For simpler tasks or ones that require immediate adaptation to new information, a reactive approach might suffice.
In practice, implementing plan-and-execute often involves a Planner prompt and an Executor loop. The planner might output a numbered to-do list, and the executor will go through them, possibly using tools (like web search, calculators, etc.) to complete each item. LangGraph’s example of this architecture shows exactly this pattern: the agent first produces a plan and then yields a trace of solving each step (e.g., find winner -> result, then find hometown -> result, and so on). The result is a coherent solution built step-by-step, but guided by an upfront game plan.
Compared to ReAct, Plan-and-Execute can be more efficient and less token-intensive for long tasks because it commits to a clearly defined strategy from the start, reducing the repeated prompting overhead of step-by-step reasoning. However, this initial commitment means Plan-and-Execute may require explicit replanning if unexpected results appear mid-task—for instance, if the search reveals the Australian Open winner is unknown or controversial. In such scenarios, while a ReAct agent naturally adapts by revising each step on the fly, a Plan-and-Execute agent would pause, reassess, and explicitly adjust the plan before continuing. This makes Plan-and-Execute particularly well-suited to structured tasks with predictable sub-steps, though potentially less agile in highly dynamic situations.
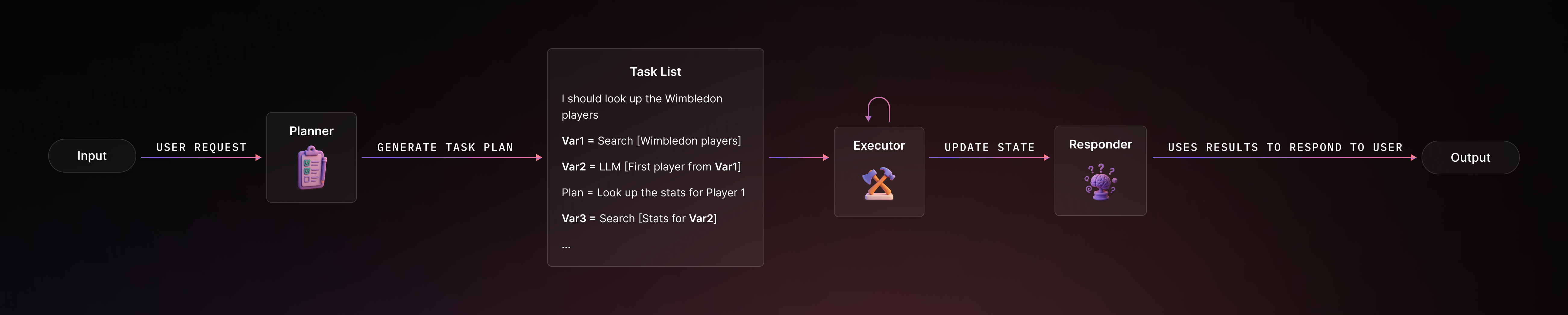
ReWOO (short for Reasoning WithOut Observation) is a relatively new agent design that can be seen as an optimization of the ReAct paradigm. That means the LLM is called every cycle to decide the next action, consuming tokens to reconsider the entire history each time. ReWOO streamlines this by having the LLM plan out the entire sequence of tool calls in one pass, before executing any of them.
In other words, ReWOO asks the LLM to produce something like a script: a chain of step-by-step instructions with the specified tools and inputs, possibly using placeholders for results of earlier steps. Only after the plan is written does the agent execute the tools in order, and finally the LLM may be called one more time to synthesize the final answer from all the gathered observations. It’s “without observation” in the sense that the initial reasoning doesn’t stop to incorporate intermediate observations – it assumes tools will work and uses variable placeholders (#E1, #E2, etc.) to reference their future outputs.
Why do this? The ReWOO paper by Xu et al. highlighted a couple of benefits:
#E1 = Google["2024 Australian Open men’s winner"]
#E2 = LLM["Who won the 2024 Australian Open? Given #E1"]
#E3 = Google["<Name> hometown"]
#E4 = Google["<Name> University X collaboration"]
#E1, #E2... are placeholders that will be filled with actual results when executed.) The LLM produced all these in one go, instead of four separate reasoning calls as ReAct would require.After planning, execution is typically straightforward: each Tool[...] step is run in sequence by a Worker module. Finally, a Solver module (often another LLM call) takes all the results #E1, #E2... and composes the final answer. In our case, the solver might take the winner’s name, hometown, and any collaboration info found, and then formulate a user-friendly answer.
Comparison with Plan-and-Execute: ReWOO and plan-and-execute share the idea of an upfront plan, but they differ in granularity. Plan-and-execute might create high-level steps (“Find winner”, “Find hometown”, “Check collaborations”) and then rely on an executor agent (which could itself be a ReAct agent) to figure out each step. ReWOO, on the other hand, plans including the tool specifics for each step (it might even decide which search queries to run, as above, using precise placeholders. Thus, ReWOO is more tightly coupled: the plan knows the exact sequence of tool usage. It’s almost like an LLM-generated program that the agent then runs.
Whereas plan-and-execute might replan after each step if needed, ReWOO by design tries to avoid re-planning during execution (it’s without intermediate observation). If a tool result is unexpected or the plan was wrong, a naive ReWOO agent could fail unless you add extra logic to catch errors. In practice, one might combine ReWOO planning with a check – for example, if a step fails or returns nothing, maybe call the planner again or fall back to a ReAct loop. So, ReWOO trades some adaptability for speed and efficiency in scenarios where you can reasonably predict the sequence of actions. For tasks like iterative web search or multi-hop questions, ReWOO can be a big win in latency. LangGraph’s tutorial shows that the LLM context for later steps can be kept minimal (thanks to the #E variable substitution) – the LLM doesn’t need to see the entire history each time, just the placeholder reference.
In summary, ReWOO is like a sibling of ReAct. Both handle multi-step tool use, but ReWOO plans the whole tool itinerary upfront. In our tennis query, a ReAct agent might have stopped after finding the winner to decide the next move, whereas ReWOO already had the “find hometown, then check collaborations” in mind from the start. This makes ReWOO more goal-directed and potentially faster, at the cost of being less interactive with intermediate results.
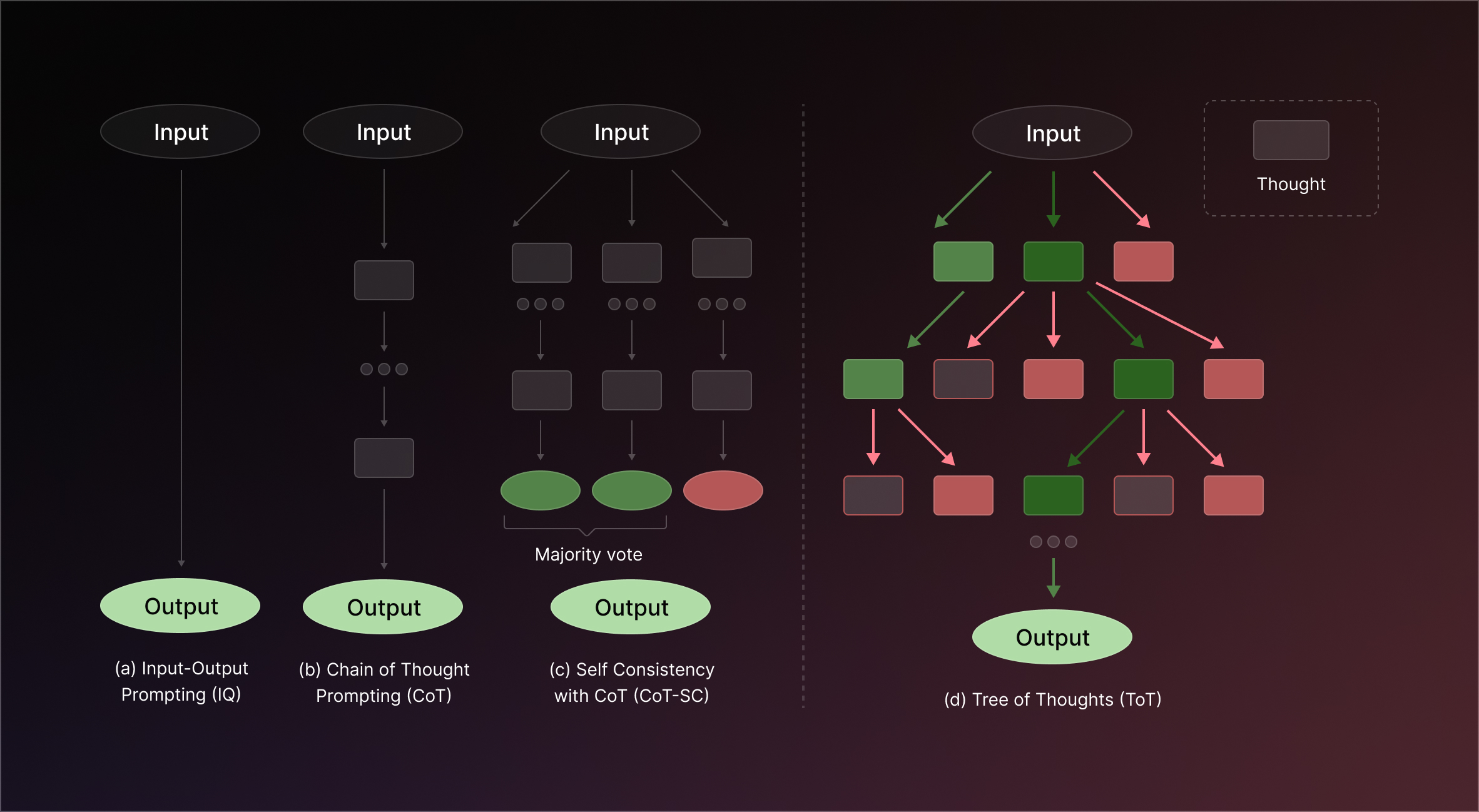
Sometimes a single line of reasoning isn’t enough – the agent might need to consider multiple possible approaches or solutions and then converge on the best one. Tree-of-Thoughts (ToT) is an algorithmic prompting technique that extends the idea of Chain-of-Thought by introducing a search over the space of thoughts. Instead of the agent following one train of thought deterministically, ToT allows it to branch out, try different partial solutions, evaluate them, and refine further, much like exploring a search tree.
Here’s how Tree-of-Thoughts works conceptually:
In essence, Tree-of-Thoughts transforms the problem-solving into a tree search (often implemented as breadth-first search, but depth-first or other strategies can be used too). It incorporates an element of reflection or evaluation at each level – the agent doesn’t blindly commit to the first thought; it systematically explores alternatives.
For our scenario, ToT might not be as necessary if the task is straightforward (the winner and hometown question is more factual). But imagine a tougher case: perhaps a riddle or a puzzle, or a planning problem with many possible plans. ToT shines in deliberative problem solving where multiple reasoning chains should be compared. For example, if the user’s query was a tricky puzzle (“Using these numbers, get 24” – which is literally the example in the LangGraph ToT tutorial), a ToT agent would generate several equations (candidates) that evaluate to 24, score them (maybe by checking if they indeed equal 24 and use all numbers), prune the wrong ones, and iterate. This methodical search yields a correct solution more reliably than a single-pass attempt that might get stuck in a dead end.
Even for planning tasks, ToT can explore different plan outlines. For instance, to answer a complicated open-ended question, one branch might represent one way of structuring the answer (e.g., by chronological narrative), another branch a different structure (e.g., by categories), and the agent can evaluate partial attempts and decide which route produces the best answer.
Relationship to other architectures: Tree-of-Thoughts is less an “agent with tools” framework and more a meta-strategy for prompting. It can be combined with tool use or purely mental simulation. In practice, ToT could wrap around a ReAct or ReWOO style approach – at each reasoning step, instead of one thought, generate several. In LangGraph, an implementation called Language Agent Tree Search (LATS) combines aspects of ToT with ReAct and planning. The core idea is giving the model the ability to backtrack and try alternatives in a structured way, rather than committing to a single chain-of-thought from the start.
To use ToT effectively, you need a way to score partial solutions. For factual tasks, an automatic check might be possible (like verifying a mathematical result). For subjective tasks, you might rely on the LLM to self-evaluate (“Does this draft answer the question fully? Score 1-10.”). Another option is to use a second model or heuristic rules as a judge.
In summary, Tree-of-Thoughts is like giving the agent a breadth of imagination. It’s powerful for complex reasoning or creative tasks where many different thoughts could lead to a solution. The cost is more computation (generating and evaluating multiple options), so it’s beneficial when a straight-line approach might fail or when you can’t easily break the task into deterministic sub-tasks. Our example query likely wouldn’t need a full ToT, but if we twisted it into a puzzle (“find a link between the tennis champion and the university”), a ToT agent might explore various hypothesis chains and ensure it finds a valid connection (or correctly concludes none exists) with higher confidence.
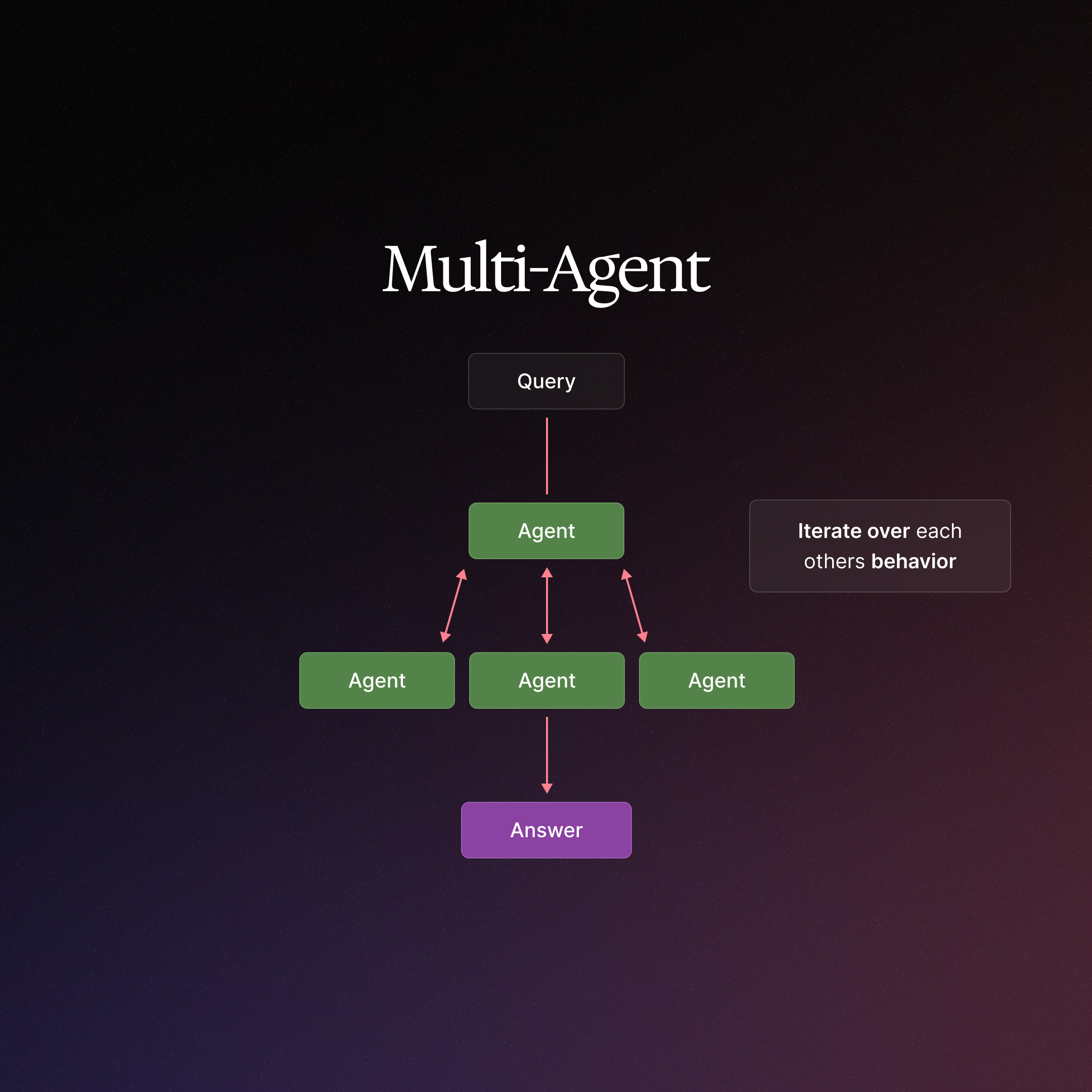
Real-world projects often require an AI to perform diverse sub-tasks or handle large context, which can overwhelm a single monolithic agent. Multi-agent architectures tackle this by splitting the problem among multiple smaller, specialized agents that work together. Each agent can be designed for a specific role or expertise – for example, one agent focused on web research, another on data analysis, and another on summarization.
Why multi-agent? As an AI application grows complex, you may encounter problems such as: too many tools or APIs for one agent to manage, a context that’s too large for one prompt, or the need for different skill sets (e.g. a “planner” vs. a “math expert”). By breaking the application into independent agents, you gain:
In our tennis question example, a multi-agent solution might deploy one agent to handle sports queries (“Who won the 2024 Australian Open?”) and another to handle academic queries (“Did that person collaborate with University X?”). A supervising agent could orchestrate the workflow: first activating the sports agent to get the winner and hometown, then passing that info to the academic agent. This modular approach keeps each agent’s context focused, reducing confusion and errors.
Multi-agent systems can be organized in different ways. Common patterns include a network (any agent can call any other next), a supervisor or hierarchy (one master agent decides which specialized agent to invoke next), or treating sub-agents as tools that a main agent can call. The choice depends on whether your problem has a clear sequence/hierarchy of tasks or is more free-form. Regardless of structure, the key benefit is clear: by delegating sub-tasks to dedicated agents, the overall system becomes more scalable and easier to manage.
Now that we’ve surveyed these architectures, how do they stack up for your project? The truth is, there’s no one-size-fits-all – each has a niche where it shines.
To circle back to our initial question use-case: a well-designed system might actually combine several of these patterns. For example, you might use a planner agent to outline the high-level approach with Plan and Execute, then spawn a research agent utilizing ReAct to dynamically gather and evaluate information, perhaps even spinning up a verification agent to double-check findings, and finally a writer agent to compile the answer. This would represent a multi-agent orchestration, internally leveraging architectures like ReAct or ReWOO for each agent's reasoning. While this may be overly complex for the tennis question scenario, it demonstrates how these architectures can complement one another effectively.
In practice, start with the simplest architecture that fits your needs and iterate. If your single agent is faltering due to complexity, consider breaking it into multi-agents. If it’s hallucinating facts, add retrieval. If it’s too slow or costly with many steps, try a planning approach or ReWOO to cut down model calls. And if it’s getting stuck on hard problems, give it a Tree-of-Thoughts boost to widen its search.
Each of these approaches was born out of specific shortcomings of a naïve LLM solution, and understanding those motivations will help you choose the right tool for the job. By leveraging the right architecture (or combination thereof), you can build AI systems that are more reliable, efficient, and capable of tackling the complex tasks you throw at them – whether it’s answering intricate questions, solving puzzles, or executing multi-step workflows.