The Illusion of Success: Why Traditional Testing Crumbles Under Autonomy
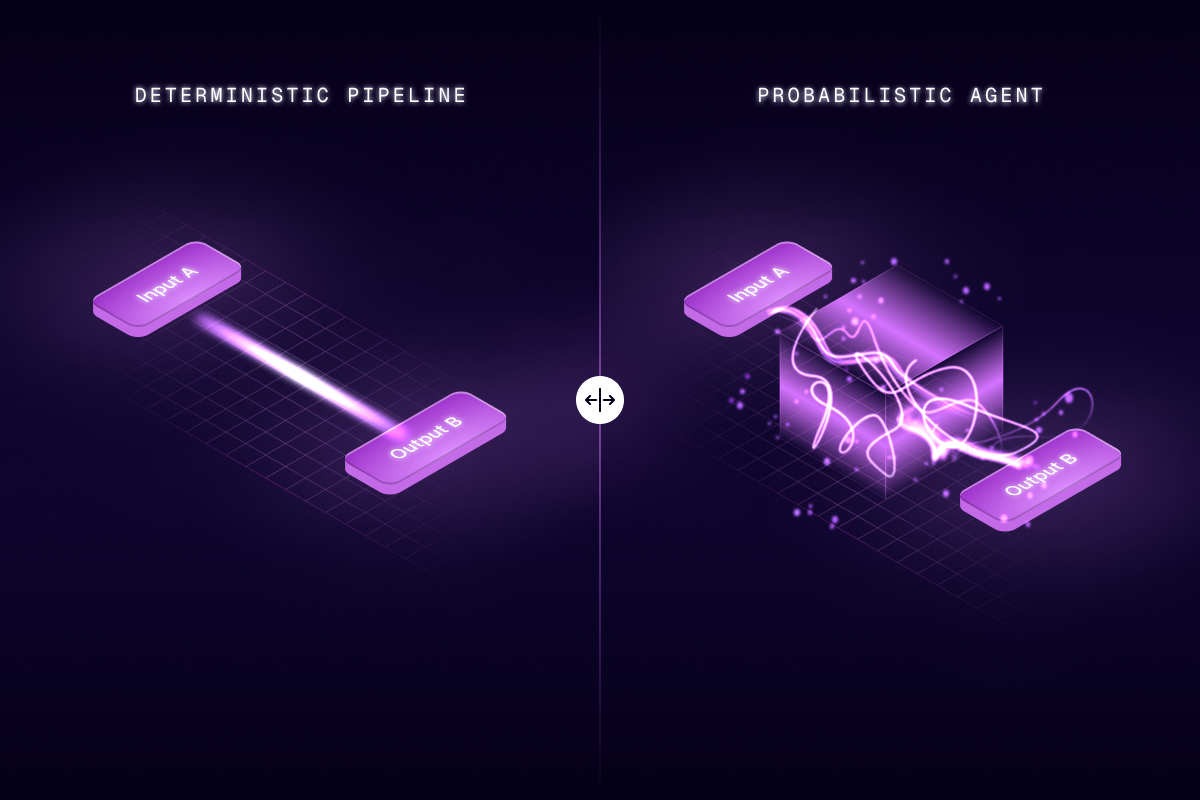
In the era of traditional software, engineering was built on a foundation of deterministic comfort. If an API received Input A, it was contractually obligated to return Output B. Testing was binary: pass or fail.
That era is over.
We are now building probabilistic machines. Agentic systems based on Large Language Models (LLMs) maintain state, reason dynamically, and wield tools with autonomy. This shift has obliterated the utility of simple input-output testing. Unlike a rigid script, the same query to an agent can generate different execution paths in different instances, turning debugging into a complex challenge of probability management.
The failures of autonomous agents are not localized; they are distributed across planning, execution, and response generation. Worse still, their internal reasoning processes often remain hidden in a "black box," making it nearly impossible to diagnose the root cause of a failure without advanced observability.
This brings us to the central problem of modern agent evaluation: a simple "input-output" test is fundamentally insufficient. It provides an illusion of functionality while hiding deep structural fragility.
Figure 1: The Illusion of Parity. Identical outputs mask radically different structural risks, where deterministic code follows a rigid rail, autonomous agents navigate a volatile, often invisible, probability map.
The New Standard: Abandoning Outcome Correctness for Trajectory Fidelity
To build systems that survive in production, we must execute a fundamental shift in our evaluation philosophy: we must move from the superficiality of "outcome correctness" to the rigor of Trajectory Fidelity. The critical question is no longer "Is the final answer correct?" but "Did the system take the optimal path to get there?"
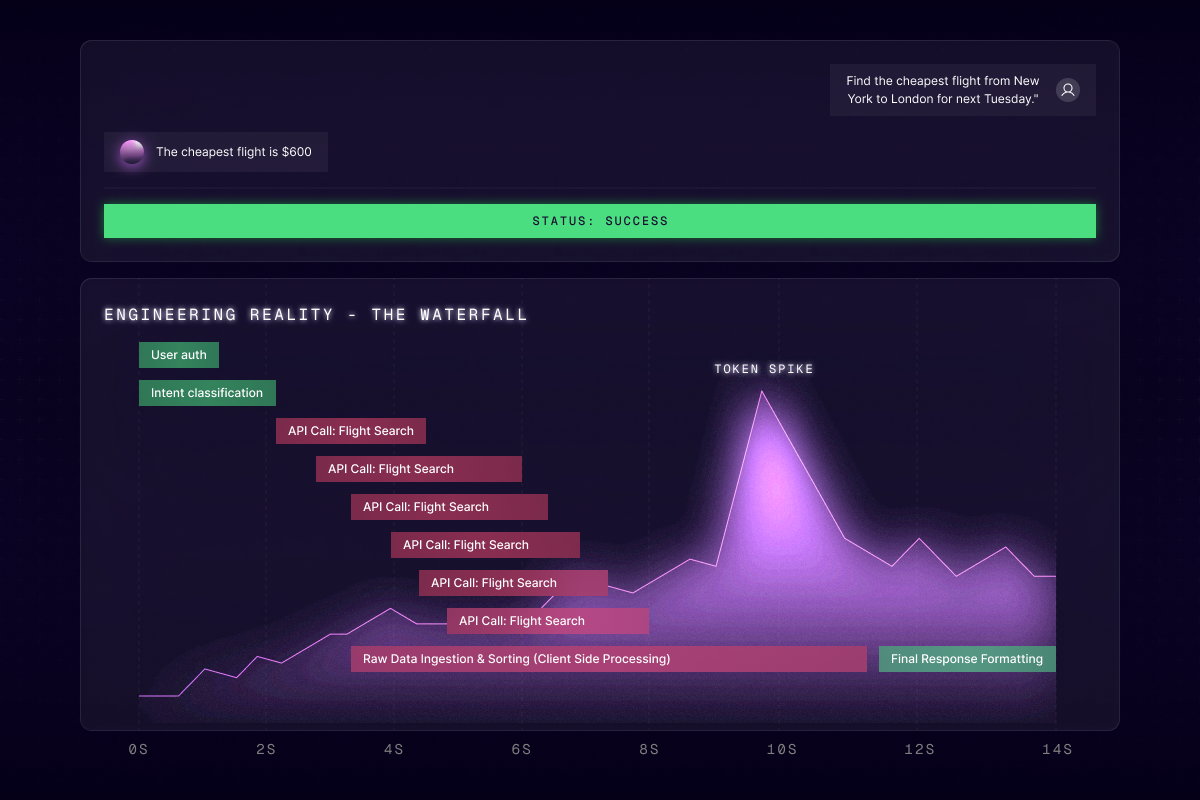
Consider the deceptive simplicity of a travel agent task: "Find the cheapest flight from New York to London for next Tuesday."
The End-to-End Result (The Illusion): The agent replies: "The cheapest flight is $600." An end-to-end test verifies the price, confirms it is accurate, and marks the test as SUCCESSFUL. The stakeholder is happy; the ticket is closed.
The Flawed Trajectory (The Reality): A review of the execution trace reveals a total design failure. Instead of a single, intelligent API call (e.g., search_flights(from='NYC', to='LON', sort_by='price')), the agent engaged in computational waste:
It called get_all_airports('New York') (retrieving 3 airports).
It called get_all_airports('London') (retrieving 3 airports).
It executed 9 separate API calls, one for every possible combination (JFK-LHR, JFK-LGW, etc.).
It received hundreds of raw flight results, loaded them all into its expensive context window—spiking token costs—and performed the sorting internally.
The agent reached the correct destination, but the path was inefficient, slow, and fragile. It multiplied costs and introduced nine times more potential failure points than necessary. Relying on a simple check of the final result gives a false sense of security.
True engineering requires us to validate the entire execution path, not just the endpoint. To address this complexity, we implement a three-layered evaluation framework that allows us to diagnose agent health from basic operations to high-level reasoning logic.
Figure 2: The "Toxic Success" Trace. A waterfall analysis reveals that a "successful" user request contained a hidden "Red Zone" of unoptimized API spam and massive token bloat, invisible to standard outcome testing.
Section 1: The Framework (Layers)
1.The Vital Signs (Operational Health & Unit Economics)
Before we can assess the "intelligence" of a system, we must audit its biological viability. These are the foundational metrics; if they fail, the sophistication of your reasoning engine is irrelevant. These metrics are quantitative, automated, and non-negotiable.
Latency: Beyond UX, this is a diagnostic signal for architectural inefficiencies like redundant tool calls or circular reasoning loops.
Cost Efficiency: We track the agent's "metabolism", token consumption and API costs per interaction, to ensure positive unit economics at scale.
Error Rate: The baseline measure of system hygiene, tracking operational failures like broken API connections and timeouts.
2.The Mission Objective (Task Success & Impact)
Here, we move beyond system health to confront the ultimate question: Did the agent achieve the strategic intent? This layer measures the tangible impact on the user's goal.
Task Completion Rate: The brutal reality of performance, measuring the exact proportion of tasks executed to satisfaction against strict criteria.
User-Centric Metrics: We utilize CSAT (Customer Satisfaction Score) and Engagement Rates to validate value, because a technically "correct" answer that frustrates the user is a strategic failure.
3.The Cognitive Audit (Trajectory and Reasoning Quality)
This is where elite engineering teams differentiate themselves. We do not just look at the destination; we audit the "mind" of the agent to validate the journey.
Trajectory Fidelity: We rigorously assess the efficiency of the path, detecting whether the agent got stuck in loops, made redundant tool calls, or explored unnecessary steps.
Tool Selection Accuracy: We verify if the agent selected the precise tool for the sub-task and constructed input parameters without hallucinating information.
RAG Precision: For retrieval-augmented systems, we measure Faithfulness (is the answer grounded in retrieved context?), Answer Relevancy, and Contextual Precision & Recall.
While Layers 1 and 2 can be automated, Layer 3 demands the "Human-in-the-Loop." Subject Matter Experts (SMEs) are indispensable for validating domain-specific correctness that automated metrics miss. We systematically harvest this feedback, not as an afterthought, but as a core asset to create a "data flywheel" that drives continuous improvement.
Figure 3 illustrates the fundamental agent evaluation metrics
Section 2: The Diagnosis
To build robust systems, we must first understand the ways they can fail. An effective error analysis begins with a systematic classification of these failure patterns.
The Taxonomy of Collapse: How Agents Fail
We categorize the failure patterns to prioritize mitigation. These are not glitches; they are structural vulnerabilities that threaten the integrity of the system.
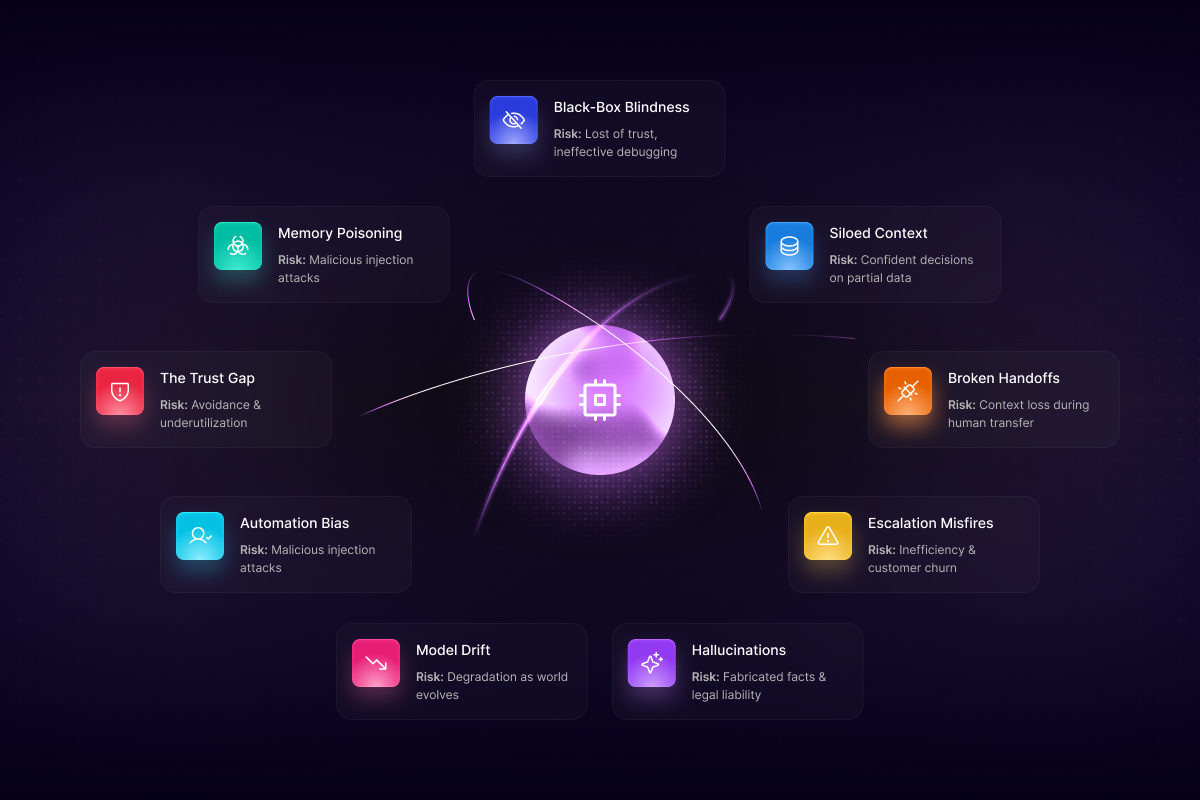
Black-Box Blindness: The inability to understand an agent's internal decision-making process. Without observability, debugging is guesswork and trust is impossible.
Siloed Context: The agent acts on incomplete information because it lacks access to data isolated in disconnected systems (e.g., a CRM vs. a support database), leading to confident but ignorant decisions.
Broken Handoffs: The destruction of context when a task transfers between AI and a human, forcing the user to repeat themselves and causing friction.
Hallucinations and False Assertions: The agent confidently generates false information (e.g., "your refund has been processed" when it hasn't), creating immediate business and legal risk.
Incorrect Decision-Making: The most dangerous failure. The agent produces flawed logic that looks correct. An infamous example is an SQL agent generating a syntactically perfect but logically flawed query (e.g., forgetting a crucial WHERE filter), delivering incorrect data that looks correct.
Model Drift: The agent's performance degrades over time as the real world evolves (new products, policies) while its static knowledge base decays.
Security Vulnerabilities: We face new attack vectors like Memory Poisoning, where an adversary injects malicious instructions into the agent's knowledge base (e.g., via a document) which the agent executes later.
The Protocol for Correction: A Data-Driven Repair Cycle
Fixing these failures should not be an exercise in random prompt tweaking. It requires a disciplined, phased process that combines qualitative and quantitative analysis to engineer reliability.
Preparation (The Golden Dataset): We begin by creating a representative "Source of Truth", a dataset of 50–100 examples that rigorously reflect the target task. Crucially, we must log all agent activity, including intermediate reasoning steps and tool calls, to ensure full visibility.
Qualitative Analysis: The team manually reviews outputs to categorize errors. We do not just fix bugs; we group them into structural categories such as "lack of knowledge," "incorrect reasoning," or "wrong output format".
Quantitative Prioritization: We quantify the frequency of each error category. This creates a data-driven, prioritized list of problems, ensuring engineering effort is focused on the highest-impact issues rather than edge cases.
Iterative Correction: We execute fixes using the Correction Hierarchy, starting with the simplest interventions. It is critical to make a single modification at a time and re-evaluate to measure its impact in isolation.The Correction Hierarchy:
Level 1: Prompt Correction. Simple changes to instructions (e.g., "Think step-by-step," "Respond only in JSON").
Level 2: Knowledge Injection. If the model lacks information, we add relevant documentation or facts directly into the prompt.
Level 3: Few-Shot Examples. If instructions are insufficient, we add concrete examples of correct input-output pairs to guide the model's reasoning.
Level 4: Flow Engineering. For systemic failures, prompt engineering is not enough. We redesign the agent's architecture, modifying control flow, tool orchestration, or memory management.
Regression Testing: After corrections, we run the entire evaluation dataset to ensure fixes haven't introduced new errors (regressions) in areas that were previously working.
Figure 4 shows a radial taxonomy mapping the nine structural vulnerabilities that threaten autonomous agent reliability.
Section 3: The Observability Arsenal: Infrastructure for Transparency
A systematic diagnostic process is useless without high-quality data to test against and the right tools to inspect agent behavior.
The Source of Truth: Engineering the Golden Dataset
A "golden dataset" is acurated collection of examples that serves as the source of truth for measuring quality. To build it, we adhere to five strict principles:
Defined Scope: We do not rely on generic benchmarks. We tailor datasets to specific tasks, separate rigorous sets for tool use, RAG faithfulness, and reasoning.
Production Fidelity: We curate examples directly from real production logs to predict actual in-field performance.
Total Diversity: We cover the entire problem space: the "happy path" (common queries), the edge cases (unusual inputs), and adversarial cases, malicious inputs designed specifically to break the agent.
Decontaminated: To ensure metrics are valid, the dataset must never overlap with the model's training data.
Dynamic Evolution: This is a living asset. We continuously update it with new failure modes discovered in production, turning every error into a future test case.
Radical Transparency: X-Raying the Black Box with Tracing
LLM Observability is the antidote to Black-Box Blindness. It is not optional; it is the difference between engineering and guessing. We achieve this through Tracing.
A trace represents the end-to-end lifecycle of a single request. It is composed of spans, which are the individual operations within the trace (e.g., an LLM call, a tool invocation, a retrieval step).
Effective tracing grants us god-mode visibility: we see exactly what the agent did step-by-step, pinpointing where reasoning paths collapsed and measuring performance (cost, latency) at the granular level. It is the bedrock upon which all meaningful error analysis is built.
The Platform Ecosystem: Choosing Your Weapons
The market has evolved beyond simple logging. We are now in the era of integrated evaluation platforms. To govern agentic systems, we select tools that offer deep observability and rigorous testing capabilities.
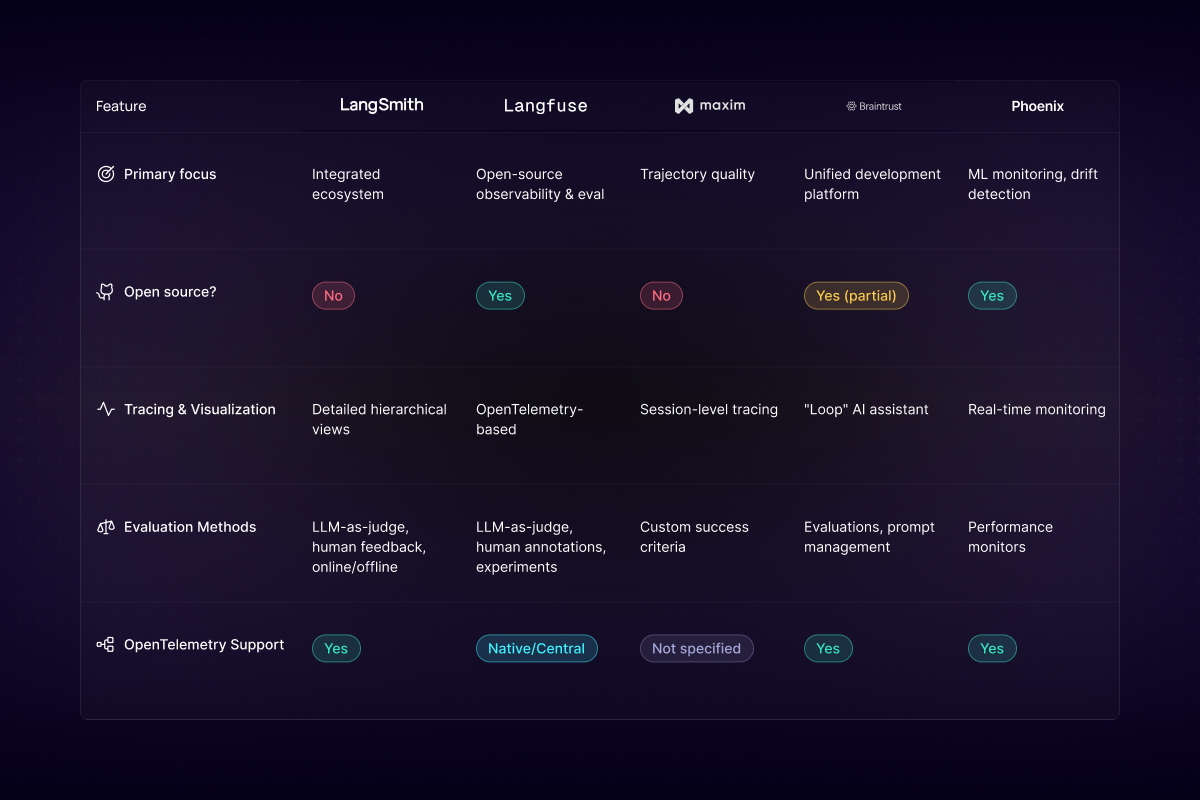
LangSmith (The Integrated Ecosystem): From the architects of LangChain, this platform offers a robust suite for observability, offline and online evaluation (including LLM-as-a-judge), and prompt management.
Langfuse (The Open-Source Standard): A powerful open-source alternative focused on tracing and prompt management, distinguished by its commitment to standards like OpenTelemetry.
Maxim.ai (The Trajectory Specialist): Positions itself as a layered evaluation platform, with a specific emphasis on trajectory quality analysis and simulation features.
Specialized Artillery: The landscape also includes Braintrust (unified platform), Arize/Phoenix (production monitoring and drift detection), and TruLens (explainability and debugging).
Strategic Integration: Evaluation is not a one-time event; it is a continuous lifecycle. It must be integrated into a CI/CD workflow, spanning local development, staging regression testing, and live production monitoring.
Figure 5 displays a comparative intelligence grid mapping the architectural capabilities and feature sets of five leading LLM observability platforms.
Conclusion: Building the Trust Layer
The path to building reliable agentic systems is paved with rigorous, continuous evaluation. Evaluation cannot be an afterthought; it must be the central pillar of the development lifecycle. To build robust, reliable, and trustworthy agents, we operate by four non-negotiable mandates:
Start Early: Evaluation begins with the very first prototype. Understanding how an agent fails is often more valuable than simply tracking how it succeeds.
The Data Flywheel: Treat every production failure and piece of user feedback as a gold nugget. Systematically convert them into new test cases for your golden dataset. This process creates a virtuous cycle where every error makes the system more antifragile.
Flow Engineering Over Prompting: Prompt engineering is tactical; Flow Engineering is strategic. Reliable performance comes from robust architecture, the design of control flow, tool orchestration, and memory. Persistent failures usually indicate a flaw in the blueprint, not the prompt.
The Hybrid Imperative: Use automated metrics for scale, speed, and operational health. But rely on human experts (SMEs) for nuanced evaluation, domain-specific correctness, and safety validation.
As agents become autonomous and integrated into the fabric of our economy, the need for transparent observability becomes paramount. The ultimate goal is to advance to a state where agent evaluation is as rigorous as traditional software testing, enabling the creation of a new generation of systems that truly earn our trust.