
The future will not be built on technology alone. It will be built on trust. At Wollen Labs, we are a catalyst for change, committed to building groundbreaking technology that redefine what’s possible. But to do that, we must confront a silent, unseen threat that lurks within the very systems we create: algorithmic bias.
The promise of AI is its ability to learn from data, but this learning can amplify society’s deeply ingrained biases if left unchecked. A predictive model in healthcare might seem to perform flawlessly on aggregate, yet it could systematically under-predict risk for a certain demographic. A hiring algorithm might appear efficient, but it could inadvertently perpetuate historical inequalities by favoring one group over another.
For any founder or executive on a world-changing mission, this isn't a theoretical problem—it's a foundational vulnerability. Building trustworthy, AI-native solutions from first principles isn't a feature; it's a strategic imperative. It requires an obsession with quality, a relentless commitment to fairness, and the technical courage to look beyond surface-level metrics.
In this article, we'll open up our playbook. We'll provide a technical blueprint for proactively identifying and mitigating algorithmic bias, revealing how we engineer fairness into every stage of the AI development lifecycle. The path to outsized impact is paved with integrity, and this is how we forge that path.
Our mission is to build AI-native solutions that redefine industries, but a relentless focus on aggregate performance metrics can become a silent sabotage. A groundbreaking product can appear to be a triumph on paper, flawless in its overall accuracy, while masking a critical, foundational flaw: a systematic bias against specific user groups.
Consider a predictive healthcare model. It might be praised for its high accuracy in flagging high-risk patients for intervention. But when you dissect its performance, you might discover it is systematically under-predicting risk for a critical demographic. The aggregate metric told you the system was a success. The granular view reveals a strategic vulnerability that could fail a world-changing mission.
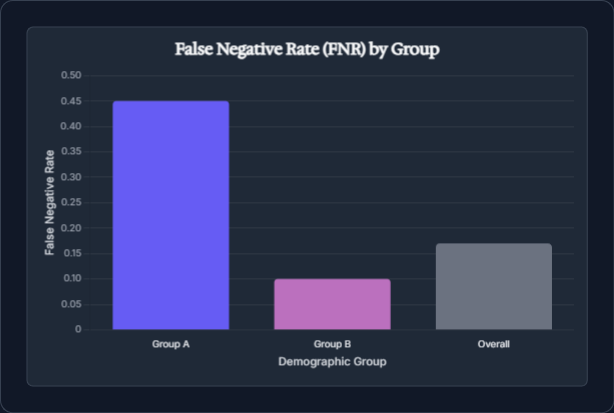
This is why we do not simply rely on global accuracy. We demand an obsession with quality that forces us to peek under the hood at the core of our intelligent systems. We relentlessly disaggregate model performance and scrutinize error rates for every demographic group. For us, a key metric isn't just the overall False Negative Rate (FNR); it's the FNR for each group. By calculating a metric like FNRk = P( Ŷ = 0 | Y = 1 ∧ G = k) for every slice of the population, we shine a light on biases that aggregate metrics so effectively hide.
This is not an academic exercise; it is the uncompromising standard of building a product that can stand up to real-world scrutiny. The disparities we uncover may be subtle, but they have outsized impact. A hiring algorithm may accept 60% of applications from one gender and only 30% from another. This is not a "bug"; it is a systemic failure of integrity.
At Wollen Labs, our AI-first mindset means we proactively identify bias from the very beginning. We scrutinize performance across every segment of the population, checking data distributions and model outcomes early and often. It's the only way to ensure the intelligent systems we build have a code of conscience embedded in their very architecture.
The quest for fair AI is not an afterthought to be addressed in deployment; it is a foundational imperative that begins long before a single line of model code is written. For a visionary founder, the first line of defense is a relentless pursuit of data integrity.
Bias can stealthily infiltrate our systems through unrepresentative datasets, flawed labels, or features that serve as proxies for sensitive attributes like race or gender. A common, and strategically dangerous, misconception is that we can achieve "fairness through unawareness" by simply omitting protected attributes. This is a fatal flaw. In practice, other features are so highly correlated with these sensitive attributes that the model will simply infer them, allowing bias to creep in through the back door. The only way to combat this is with an unwavering commitment to a comprehensive data audit.
The most critical questions we ask during this phase are:
In some industries, historical data is already tainted by systemic bias. If a model is trained to predict outcomes from this data (such as past hiring or loan decisions) it will, by its very nature, perpetuate that same bias. Blindly optimizing for such an outcome is not a path to progress; it is a path to amplifying injustice. The brightest minds on a world-changing mission must possess the courage to re-frame the problem or, if fairness cannot be guaranteed, reconsider using AI for that specific decision altogether.
Only by proactively auditing and transforming our data can we ensure that the intelligence we embed into our solutions is not just powerful, but principled. We must audit our features for proxy signals, and in some cases, it may even be necessary to include a protected attribute in the dataset for the explicit purpose of measuring and mitigating bias. We can't fix what we refuse to measure. This is the first, non-negotiable step in architecting a trustworthy AI solution from the ground up.
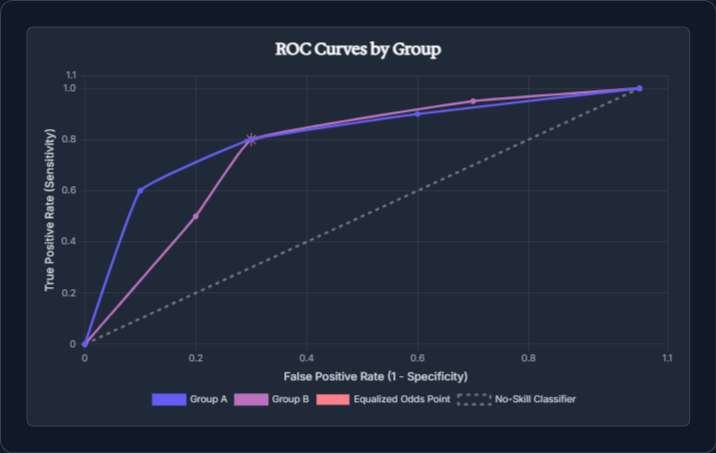
To architect intelligent systems with an unyielding code of conscience, we must move beyond a mere philosophical commitment to a precise, technical one. This requires an engineer’s toolkit of fairness metrics and a deep understanding of their inherent trade-offs.
There is no single definition of "fairness" in AI; it is a strategic choice, and one that requires the brightest minds to make deliberately. Several standard criteria exist, each capturing a different intuition about equality:
The most critical insight for any founder to grasp is that these criteria often cannot all be satisfied at once. An influential 2016 paper on "Inherent Trade-Offs in the Fair Determination of Risk Scores" proved that, in almost any realistic scenario, you cannot simultaneously achieve both calibration and error rate equality. Intuitively, if one group has a lower underlying prevalence of a positive outcome, a calibrated model will correctly account for this difference, which can then cause a disparity in recall or false negatives.
This forces a strategic decision. Is it more critical that all groups receive positive opportunities at the same rate, or that when the model predicts success, it is equally reliable for everyone? There is no one-size-fits-all answer. A university admissions tool might prioritize Equal Opportunity to ensure no qualified student is left behind, while a bank may prioritize Calibration to ensure credit scores have an equal meaning across all demographics. Navigating these trade-offs is where elite collaboration and an obsession with quality truly make the difference. It is not just a technical challenge; it is a core strategic choice that defines the integrity of your solution.
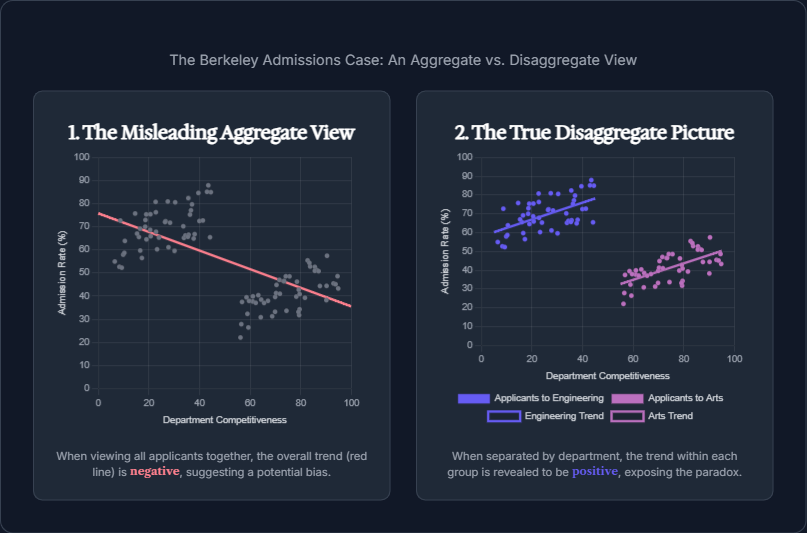
The brightest minds know that true technical excellence lies beyond the surface of a data point. While metrics are essential, an AI-native product's integrity is ultimately defined by our ability to understand causation, not just correlation. This is a strategic imperative that requires a commitment to a higher level of thinking.
We believe that every founder must ask a critical question: is an observed disparity in the data truly due to bias, or is it a result of a confounding variable? The classic Berkeley admissions case illustrates this perfectly: what appeared to be a significant gender disparity was, in fact, an outcome of department choice. The women applicants tended to apply to more competitive departments, which had lower admission rates across the board. The bias was not a direct effect of gender, but a hidden variable influencing the outcome. Without a causal understanding, a leader might have attempted to "correct" for the wrong problem, creating a new form of injustice.
This foundational insight leads to the most powerful tool in our arsenal: counterfactual fairness. This is a conceptually powerful idea that aligns with a human sense of justice. We ask: "If we could hypothetically change a person's protected attribute, holding everything else constant, would the intelligent system’s decision change?" A model is counterfactually fair if, for any individual, the prediction is the same in the actual world as it would be in an alternate world where the individual belonged to a different demographic group. This is the ultimate test of integrity; it forces us to build systems that treat individuals on their merits, free from a dependency on group identity.
Because fairness is a human value judgment, we understand that technology is a tool, not a solution in itself. This is why we incorporate human-in-the-loop governance into our processes. Our commitment to an unyielding code of conscience means we establish ethics reviews where diverse teams and stakeholders can scrutinize model behavior. We also provide a Model Card for every solution, a declaration of transparency that documents the known limitations and the strategic trade-offs that were made. This level of openness builds trust, both internally and with our visionary partners.

The AI-Native Blueprint: Integrating Ethics from First Code
Delivering AI-native solutions that possess both intelligence and integrity is not a one-off task; it is a strategic, end-to-end mission that must be woven throughout every phase of the development lifecycle. This is our playbook. Fairness is a living requirement, not a feature we can bolt on at the end.
This is how we operationalize our ethical principles:
1. Set Clear Fairness Goals from the Start: Before we write a single line of code, we align on a clear ethical north star. We make a deliberate, strategic decision on which fairness criteria—be it demographic parity or equalized odds—aligns with the product's mission and the outsized impact we are relentlessly pursuing. These goals become first-class metrics, signaling to every member of the elite collaboration that integrity is a non-negotiable component of success.
2. Audit and Improve Data Quality: The quest for a world-changing product begins with an uncompromising commitment to data integrity. We perform a foundational bias audit on every dataset. We relentlessly check for historical biases, and we have the courage to ask if the data's target outcome is a true measure of merit or simply a reflection of past prejudice. If the data is flawed, we do not proceed. We believe that sometimes, the only way to reduce bias is to invest the effort and sacrifice required to gather a more balanced, representative dataset.
3. Mitigate Bias with Technical Precision: When unfairness is detected, we deploy an arsenal of technical strategies, each with its own trade-offs:
4. Monitor and Iterate in Production: For us, deployment is not the end of the journey; it is a new beginning. We continuously monitor the model's outcomes in the real world, using our chosen fairness metrics as a guide. Population dynamics can shift, and a model can drift, leading to new and emerging biases. We are prepared to address these with the same urgency as any other technical flaw. We treat fairness as a living requirement, a process of continuous improvement that every elite team must embrace.
In some cases, the most ethical solution is not to deploy an AI at all. If, after all our effort and sacrifice, we find that the model's predictions would amplify an unjust status quo, we possess the integrity to say "no." Technology should not be a fig leaf for entrenched inequalities; it must be a force for positive change.
We believe in a relentless commitment to transparent and principled development. Here’s how we do it:
Finally, we acknowledge the most difficult, and most crucial, step: the integrity to say "no." If, after all our effort and sacrifice, we find that a model's predictions would reflect or amplify an unjust status quo, we possess the courage to return to the drawing board. A groundbreaking AI solution should never be a fig leaf for entrenched inequalities. We must be willing to walk away from a technical solution when it's not the right tool for the job.
An obsession with quality is not just about perfect code or flawless metrics; it is about building trust. For any AI-native solution to achieve outsized impact, it must be perceived not as a black box or a threat, but as a collaborative force. This is a core strategic imperative we embed into our elite collaborations.
We understand that our visionary partners and their end-users must trust the intelligent systems we create. This requires us to proactively communicate our ethical safeguards and build a collaborative culture. We establish feedback loops so that expert knowledge from our partners continuously refines the logic of the AI agents. By empowering them to question, critique, and provide input, we foster an environment of shared ownership and ensure the AI evolves to serve their purpose, not just to optimize a number.
Ultimately, fostering the "AI as ally" mindset is the final, non-negotiable step in building a groundbreaking product. By making our ethical safeguards visible and actionable, we empower our partners to scale with integrity and build a foundation of trust that will last.
Building AI-native products that are both revolutionary and equitable is not an option; it is a strategic imperative. The intelligent systems of the future will not be judged solely on their performance but on their integrity. By proactively detecting and mitigating biases, by relentlessly navigating the complex trade-offs, and by embedding a code of conscience into every line of code, we ensure that our groundbreaking products do not just perform well, but also earn the most valuable currency in the new economy: trust.
This is the path to outsized impact. It is a path forged with integrity, courage, and a relentless commitment to treating fairness as a first-class metric. The brightest minds understand that a model that is both powerful and transparent will engender greater confidence, face lower regulatory risk, and ultimately deliver more sustained value. This is how we redefine what's possible and build a future where AI is not just a tool, but a trusted ally in a world-changing mission.
At Wollen Labs, we engage in elite collaborations to build groundbreaking AI solutions. If you are a founder or executive ready to redefine what's possible in your industry, Book a strategic call with our leadership team.